Introduction:
Python is a high-level coding language that provides vast libraries to perform various tasks, including web scraping. Web scraping is a technique to extract data from websites automatically. This tutorial will explain how to scrape data from websites using Python step-by-step.
Table of Contents:
- What is web scraping?
- Why use Python for web scraping?
- Libraries required for web scraping
- Steps for web scraping using Python
- Best practices for web scraping with Python
What is Web Scraping?
Web scraping is an activity of extracting a massive amount of information from any website. It involves an automatic way of extracting information from the internet without needing any manual intervention. For instance, information such as product prices, customer reviews, stock market data, social media profiles, and news articles can be scrapped using web scrapping techniques.
Why use Python for web scraping?
The Python programming language is considered one of the best for web scraping. The reasons for this choice are multiple. Python has easy-to-learn syntax, ample libraries that can be used for various tasks, and it is an open-source programming language. Python is also known for its high-level object-oriented programming, which makes development projects faster and maintainable.
Libraries required for web scraping
Python has several libraries for web scraping, but the following libraries are the most commonly used in Python Programming.
- BeautifulSoup – Used for web scraping HTML and XML documents.
- scrapy – A web scraping framework that provides a high-level API for web scraping.
- requests – A simple library for pulling data from websites
- Selenium – A browser automation tool used to automate tests on web applications.
Steps for web scraping using Python
- Identify the data you want to extract.
We want a list of quotes. - Get the URL of the webpage from which you want to extract data
http://quotes.toscrape.com – This website is built for practicing web scraping and doesn’t violate any terms of service. - Analyze the structure of the webpage
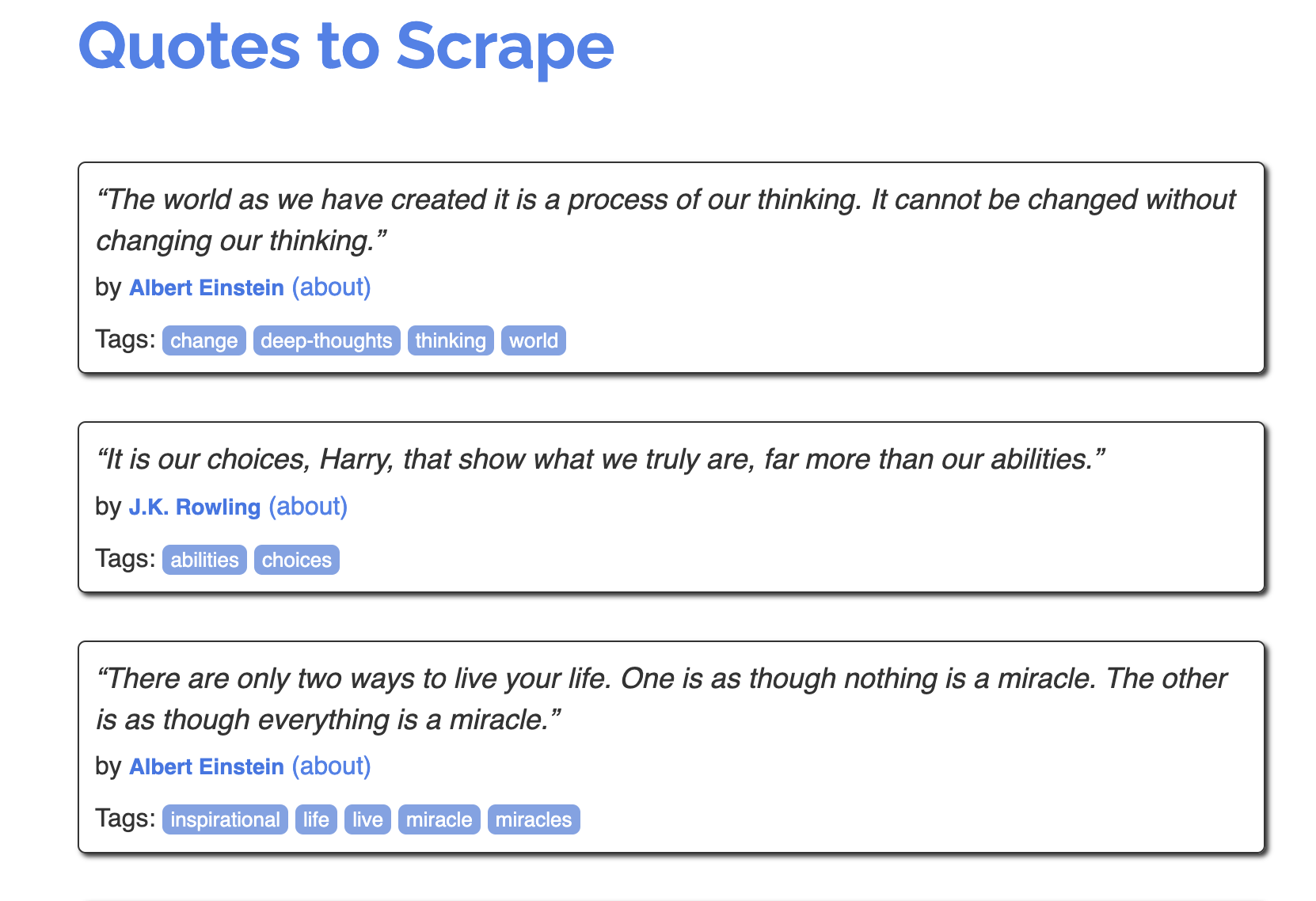
- Analyze the markup of the webpage.

- Set up your environment: Install the required libraries. Use pip:
pip install beautifulsoup4 requests- Write your script: Here’s a simple script that scrapes the quotes from the first page of “http://quotes.toscrape.com”.
import requests
from bs4 import BeautifulSoup
def scrape_quotes(url):
# Fetch the page content
response = requests.get(url)
if response.status_code != 200:
raise Exception(f"Failed to load page. Status code: {response.status_code}")
# Parse the content with BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract quotes using the specific class name
quotes_divs = soup.find_all("div", class_="quote")
for quote_div in quotes_divs:
# Extract the text of the quote
quote = quote_div.find("span", class_="text").text
# Extract the author of the quote
author = quote_div.find("small", class_="author").text
print(f"{quote} - {author}")
if __name__ == "__main__":
URL = "http://quotes.toscrape.com"
scrape_quotes(URL)
- Run the script: Once you’ve written the script, simply execute the Python file:
python your_script_name.py- Analyze the output: You should see the quotes and authors printed on your console.
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.” - Albert Einstein
“It is our choices, Harry, that show what we truly are, far more than our abilities.” - J.K. Rowling
“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.” - Albert Einstein
“The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.” - Jane Austen
“Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.” - Marilyn Monroe
“Try not to become a man of success. Rather become a man of value.” - Albert Einstein
“It is better to be hated for what you are than to be loved for what you are not.” - André Gide
“I have not failed. I've just found 10,000 ways that won't work.” - Thomas A. Edison
“A woman is like a tea bag; you never know how strong it is until it's in hot water.” - Eleanor Roosevelt
“A day without sunshine is like, you know, night.” - Steve Martin
Best practices for web scraping with Python
- Always identify yourself by providing your contact information so that the webmaster could contact you in case of any issue during scraping.
- Use appropriate headers and User Agents to pretend as a human user and avoid being blocked or detected by web hosts.
- Check the web scraping rules of the website that you are scraping and adhere to them.
- Avoid scraping websites that require authentication or login credentials
- Backoff temporarily on failed requests to avoid getting your IP address blacklisted
Conclusion:
Web scraping is a popular process, and Python is an efficient language for web scraping tasks. Python’s versatility and diversity of libraries make it a perfect choice for web scraping. This tutorial has presented a step-by-step process for web scraping with Python. It is essential to follow best practices and adhere to web scraping rules to avoid issues while scraping data.
Frequently Asked Questions:
1. What is web scraping?
Web scraping is the process of automatically extracting information from websites using a script or program.
2. Why use Python for web scraping?
Python is a popular language for web scraping due to its ease of use, vast number of libraries and frameworks available, and its ability to handle large amounts of data.
3. What libraries are required for web scraping with Python?
The commonly used libraries for web scraping include BeautifulSoup, Scrapy, Requests, and Selenium.
4. What are the steps involved in web scraping with Python?
The steps for web scraping with Python include identifying the data you want to extract, analyzing the webpage structure, sending an HTTP request to the server, receiving the server’s response, parsing the page content using BeautifulSoup, finding the data to scrape, extracting the data, and storing it in a structured format.
5. What are the best practices to follow while web scraping with Python?
The best practices include identifying yourself, using appropriate headers and user agents, adhering to the website’s scraping rules, avoiding scraping websites that require authentication or login credentials, and backing off on failed requests.
6. What is Beautiful Soup?
Beautiful Soup is a Python package that is used to extract data from HTML and XML documents.
7. What is Scrapy?
Scrapy is a Python-based web crawling and web scraping framework used for extracting structured data from websites.
8. What is Requests?
Requests is a Python library used for sending HTTP requests to websites and receiving responses.
9. What is Selenium?
Selenium is a web browser automation tool used for testing and automating web applications.
10. Can web scraping be illegal?
Web scraping can be illegal if it is used for illegal purposes like stealing copyrighted content, personal information, or trade secrets. Adhering to the website’s scraping rules and using data only for legal purposes is essential.